First Responder Data 1 - Setting Up a Simple Automated ETL Data Pipeline of Public Safety Data Using Apache Airflow and RDS On AWS
Introduction
It’s been a while since I have updated this blog. A lot of things have happened both globally, and personally. All of which resulted directly from the current pandemic. For the sake of brevity I’ll omit the global events and skip to the personal news. I realized that I needed to go outside of my comfort zone, and pursue a position that was more fulfilling to my long term personal, and career ambitions. I hit the job market shortly after that realization, and came away with a great full time position in Seattle. My family and I relocated to Seattle from New Mexico.
Now that I have settled in and absorbed the city life (as well as the fantastic weather and parks), I have decided to shift my focus back to this blog. A lot of the content on this blog is focused on deliverable analysis and insights, but I do have an interest in back-end and data ETL (Extract - Transform -Loading of data) work.
Objectives
After familiarizing myself with some of Amazon’s web services, I though I’d use some of its resources to develop a small project. I set up an automated data pipeline from the city of Seattle’s public data source to a database I spun-up on AWS. The goal of this project is to store data on my database that would be readily available for analysis. This would mitigate approaching or exceeding any quota limits due to repeated calls from analytics, geocoding, etc. Most of this article will be written in Python, as I’ve started utilizing it more frequently.
To create an automated data pipeline, we need a streamlined tool that will help us set it and forget it. Cue Apache Airflow, which is a very robust and illustrative way to manage, deploy, and monitor automated ETLs and workflows. Airflow works by setting up processes as DAGs (Direct Acyclic Graphs), that are compromised of tasks you’d like to run in your workflow. The tasks don’t necessarily need to be in Python, but it definitely helps, as all of the framework for Airflow is developed in Python. Each task is run by using an operator, such as a Python, or Bash operator. R operators are not currently supported, but you could call an R script using the bash operator. However, since our ETL work flow is relatively simple, we’ll keep it simple by using the Python operator.
The data we will be working with in this article, is public saftey data from the city of Seattle. It is a ledger of each 911 call that resulted in a fire department dispatch. The data is relatively simple, and includes the city of Seattle’s incident code, incident type, the geographic point in latitude-longitude pairs, as well as the date-time of ocurrences, and reports.
ETL Pipeline Description
The image below illustrates our simple ETL work flow. It’s worth noting that Airflow records the task and DAG logging automatically in SQLite by default. However, if you wish to store the record logs in a different SQL environment, Airflow has some support for that as well. We’ll be using the default event and task logging that comes out of the box.
Let’s go over the rest of the system components. The Seattle Public data will be coming from the Socrata API endpoint that is utilized by the city of Seattle. This is a standard API interface where you can easily query data based on multiple criterion. The Apache Airflow instance is something that we’ll delve into further in this article. It’s basically just a very flexible and robust system that allows you to schedule and deploy bash and python scripts. It also allows you to establish “connection hooks” to external data sources, which is very helpful when managing data pipelines to and from various systems. One great thing about Airflow, is that it has a nifty GUI, that allows you to audit event logging, and keep track of prior deployment statuses.
The destination of our data will be a PostgreSQL database instance, that I have spun up on RDS in AWS. It’s pretty easy to do, and you don’t have to use a Postgres database. RDS on AWS supports MariaDB, MySQL, Oracle, and MSSQL Server. I have already created the database tables we’ll be funneling data into. You could use a tool like SQLWorkbenchJ to perform a simple query to create the table (but you’ll have to explicitly declare the classes), or you could import some sample data into the database via psycopg2 beforehand, just to make sure you avoid any data type errors.

ETL Diagram
Methods
Set Up
Let’s set up the ETL pipeline to schedule and deploy. To install Airflow, I used a neat article written by David Barlow, that you can find here. Some familiarity with AWS is needed. In particular, you have to have some knowledge of deploying EC2 (Elastic Computing Cloud) instances, setting up permissions in a VPC (Virtual Computing Cloud), and working with a Linux CLI (Command Line Interface). David Barlow recommends using a Jupyter Notebook environment in conjunction with Airflow, which I also prefer. In addition to this, it’s recommended that you install airflow, and the jupyter notebook services in a separate python virtual environment. This will help isolate any dependency errors or inconsistencies resulting from package updates.
The set up of airflow, the EC2 instance, and the VPC, can be quite time consuming. The most frustrating, and annoying thing to deal with though is also the perpetual source of chagrin for most developers and data folk: database drivers. Oh boy, don’t get me started on database drivers. Most of them cause a significant amount of pain and anguish, but none however are as terrible, inconceivably frustrating, and cause as much torture as MSSQL drivers. Since we’re utilizing PostgreSQL in this project, I’ll avoid expanding further on this topic. Once you have installed a database driver, you can set up a what’s known as a “Connection Hook” in Airflow. A connection hook is just another name for a connection to an external interface. The great thing about it, is that once it’s set up, using it is as easy as calling a method. Another bonus is that you’re able to run ad-hoc queries on your connection hook via Airflow’s web front-end.
I’ve already configured the connection hook to my PostgreSQL database. In the screen capture below, I’m running a simple query where I count all of the 911 incident “types” in the CleanFireCalls table.

Ad-Hoc Query
Tasks
The Extraction and Loading tasks illustrated in the diagram above, will be accomplished by the triggering of two tasks which we’ll refer to as tasks run_insert_f911 and Inserting_distinct. These tasks trigger two functions InsertingTheCalls and clean_firecalls respectively. Let’s take a look at InsertingTheCalls:
def InsertingTheCalls(ds, **kwargs):
### Connect to postgres server
postgresserver = PostgresHook('Postgres Jcaro')
### Connect to seattle public data portal via Socrata
client = Socrata("data.seattle.gov",
"AxejqJVsnt6qbNhpmUDUtz8um",
username=username_SOC,
password=password_SOC)
##Test print date
print(datetime.date.today())
now_pt = datetime.datetime.now() - datetime.timedelta(hours=8)
filter_time = now_pt - datetime.timedelta(minutes = 20)
#filter_time = filter_time.isoformat()
formatted_filter = filter_time.strftime("%Y-%m-%dT%H:%M:%S")
formatted_filter = str(formatted_filter)
## Test filter print
print(formatted_filter)
filter = "datetime >= '" + formatted_filter + "'"
print(filter)
### Get data after or equal to filter time
results = client.get("kzjm-xkqj",where = filter, limit=50)
# Convert to pandas DataFrame
results_df = pd.DataFrame.from_records(results)
results_df = results_df.loc[:,"address":"incident_number"]
calls_df = results_df
calls_df["report_location"] = "point"
calls_df.rename({"report_location":"report_location.type"})
print(calls_df)
### Convert to tuples for inserting
calls_tuple = [tuple(r) for r in calls_df.to_numpy()]
### Insert into postgres
postgresserver.insert_rows("public.seattlefirecalls", calls_tuple,commit_every =1)First we begin by defining our connection hook postgresserver to point to the PostgreSQL database. Then, we define our connection to the SOCRATA API (using sodapy). We print the current date, and then subtract 8 hours to the current system time (difference between UTC and PST). We plan on querying the SOCRATA API for the all of the calls in the previous 75 minutes, so we declare filter_time as the current time in PST, minus 75 minutes. We then format filter_time to a string which is compatible with the SOCRATA API endpoint, and create the actual filter string, subsequently calling the endpoint for the pertinent data, and storing the data in results_df.
Here’s what the results from the query look like:
results_df.head()| address | type | datetime | latitude | longitude | report_location | incident_number |
|---|---|---|---|---|---|---|
| 4th Ave / Cherry St | Trans to AMR | 2020-11-30T14:12:00.000 | 47.603948 | -122.330952 | Point , -122.330952, 47.603948 | F200117358 |
| 1200 19th Ave E | Aid Response | 2020-11-30T14:13:00.000 | 47.630617 | -122.307246 | Point , -122.307246, 47.630617 | F200117359 |
| 1600 7th Av | Aid Response | 2020-11-30T14:22:00.000 | 47.6126 | -122.334262 | Point , -122.334262, 47.6126 | F200117362 |
| N 36th St / Fremont Ave N | Aid Response | 2020-11-30T14:31:00.000 | 47.651349 | -122.349934 | Point , -122.349934, 47.651349 | F200117364 |
| 3rd Ave / Pike St | Trans to AMR | 2020-11-30T14:36:00.000 | 47.60975 | -122.337793 | Point , -122.337793, 47.60975 | F200117368 |
| Sw Morgan St / 37th Ave Sw | MVI - Motor Vehicle Incident | 2020-11-30T14:40:00.000 | 47.544731 | -122.379139 | Point , -122.379139, 47.544731 | F200117366 |
Afterwards, we subset the dataframe results_df, subsequently coercing it to a tuple and inserting it into the PostgreSQL table public.seattlefirecalls via Airflow’s insert_rows() method.
This task scheduled to run every 15 minutes. Since there is a slight lag in execution time between the scheduled start time, and the actual start time, I add a buffer of 5 minutes to the data I query from the SOCRATA API. It’s worth noting there is a slight misnomer between what one might define to be an execution time, and what Airflow designates as the execution time. In Airflow, if I run a task every 15 minutes, a task scheduled to be executed at 12:45 PM won’t actually fire until around 1:00 PM. The reason is described here on stack overflow.
Since I built in the 5 minute buffer we run the risk of inserting duplicate data into the table. To resolve this issue, we can proceed two ways. We can use the python environment to query the table we’re inserting the data into and do an except join with our new data. This would effectively filter out the duplicate data already contained in our PostgreSQL table. Another way to resolve this issue, is to use an auxiliary table in our PostgreSQL database, and have our postgres instance do this for us through a quick except (left anti-join) SQL statement. I have chosen the latter, due to a restriction of resources on my EC2 instance.
The task aptly titled Inserting_distinct, triggers the function clean_firecalls. Let’s take a look at the function:
def clean_firecalls(ds, **kwargs):
### Define connection to postgres DB
postgresserver = PostgresHook('Postgres Jcaro')
#### Insert into the clean table
postgresserver.run("insert into public.cleanfirecalls (select * from public.seattlefirecalls except / (select * from public.cleanfirecalls))", autocommit = True)
#### Delete data after insert
postgresserver.run("delete from public.seattlefirecalls where true", autocommit = True)After defining the function, I define my connection hook as postgresserver, and then I run two commands. First, I tell the database to insert data from public.seattlefirecalls that is not already present in public.cleanfirecalls. Then I simply delete the data in public.cleanfirecalls, as it’s already been inserted into public.cleanfirecalls.
Creating the actual DAG.
Now that we have our two functions, we’re ready to create the actual DAG of tasks for Airflow to run. Our DAG is pretty simple, it’s just run_insert_f911 >> insert_distinct, as you’ll see below.
from airflow.utils.dates import days_ago
from airflow.hooks.postgres_hook import PostgresHook
from airflow.models.connection import Connection
import psycopg2
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
import datetime
from sodapy import Socrata
import pandas as pd
args = {
'owner': 'JCaro',
}
dag = DAG(
dag_id='insert_latest_calls',
start_date=datetime.datetime(2020, 10, 22),
schedule_interval=datetime.timedelta(minutes = 15),
tags=['Seattle 911 Fire'],
)
# [START Get calls]
def InsertingTheCalls(ds, **kwargs):
### Connect to postgres server
postgresserver = PostgresHook('Postgres Jcaro')
### Connect to seattle public data portal via Socrata
client = Socrata("data.seattle.gov",
"AxejqJVsnt6qbNhpmUDUtz8um",
username= username_SOC,
password= password_SOC)
##Test print date
print(datetime.date.today())
now_pt = datetime.datetime.now() - datetime.timedelta(hours=8)
filter_time = now_pt - datetime.timedelta(minutes = 20)
#filter_time = filter_time.isoformat()
formatted_filter = filter_time.strftime("%Y-%m-%dT%H:%M:%S")
formatted_filter = str(formatted_filter)
## Test filter print
print(formatted_filter)
filter = "datetime >= '" + formatted_filter + "'"
print(filter)
### Get data after or equal to filter time
results = client.get("kzjm-xkqj",where = filter, limit=50)
# Convert to pandas DataFrame
results_df = pd.DataFrame.from_records(results)
results_df = results_df.loc[:,"address":"incident_number"]
calls_df = results_df
calls_df["report_location"] = "point"
calls_df.rename({"report_location":"report_location.type"})
print(calls_df)
### Convert to tuples for inserting
calls_tuple = [tuple(r) for r in calls_df.to_numpy()]
### Insert into postgres
postgresserver.insert_rows("public.seattlefirecalls", calls_tuple,commit_every =1)
def clean_firecalls(ds, **kwargs):
### Define connection to postgres DB
postgresserver = PostgresHook('Postgres Jcaro')
#### Insert into the clean table
postgresserver.run("insert into public.cleanfirecalls (select * from public.seattlefirecalls except (select * from public.cleanfirecalls))", autocommit = True)
#### Delete data after insert
postgresserver.run("delete from public.seattlefirecalls where true", autocommit = True)
run_insert_f911 = PythonOperator(
task_id='InsertingTheCalls',
provide_context=True,
python_callable=InsertingTheCalls,
dag=dag,
)
insert_distinct = PythonOperator(
task_id='Inserting_distinct',
provide_context=True,
python_callable=clean_firecalls,
dag=dag,
)
run_insert_f911 >> insert_distinctAfter importing all of our necessary libraries, we define our DAG as insert_latest_calls. We schedule it to run every 15 minutes, starting on 2020-10-22. We provide the two functions we’ll be utilizing in this DAG, as well as the the tasks that actually execute the functions in airflow. We have named these tasks run_insert_f911 and insert_distinct. The final line denotes our elementary DAG. First we run run_insert_f911, and after that task is completed, we run insert_distinct. Airflow makes sure that insert_distinct won’t run until the prior task is complete.
Final Product
Tools
Now that we have successfully deployed our ETL pipeline, we can take a look at some neat tools Airflow offers. The first tool is the task monitor. It allows you to see the duration of each task in your DAG. In the image below, you’ll see some irregular spikes in duration for the task InsertingTheCalls. It may be due to a large influx of size in the data we’re writing to our Postgres database. Although, since there are no failures, and the task durations cap out at 10 seconds, it’s not really worth investigating.

TaskMonitor
From the Airflow landing page, you can start or stop your ETL pipelines, check if any have failed, see which are running, and check the scheduled interval.

Airflow Landing
Cursory Analysis
We can easily query our database for any of the data we have loaded onto it, without affecting any API limits. In python, this involves using a library like psycopg2, and connecting to the database where we stored the data. Our database is in “the cloud”, but accessing a database in the cloud is just as easy as accessing one hosted locally on your machine.
conn = psycopg2.connect(
host= host_addr,
database="testing",
user="jcaropostgres",
password=user_pw)
def sqlQuery(querystr):
getquer = pd.read_sql(querystr, conn)
return(getquer)
firecalls_df = sqlQuery("SELECT * FROM public.cleanfirecalls where datetime < '2020-11-28' and datetime >= '2020-11-13'")
top5_types = firecalls_df.groupby("type", as_index = False).\
agg(typecount = pd.NamedAgg("type", "count")).\
sort_values("typecount", ascending = False).iloc[1:6].type
After connecting to our database, we define a quick function that makes repeated querying much easier. We’ll call it sqlQuery, and all we have to supply to it is the query string. That is the query statement in a string data type. Here, we’ll query all of the data from the table public.cleanfirecalls between (and including) 2020-11-13 and 2020-11-27. We then declare top5_types, as a series of the top 5 highest incident type by ocurrences.
firecalls_df = firecalls_df.loc[:,["type", "datetime", "incident_number"]][firecalls_df["type"].\
isin(top5_types)]
firecalls_df = firecalls_df.assign(date = lambda x: x["datetime"].dt.date)
firecalls_count_df = firecalls_df.groupby(["type", "date"], as_index = False).\
agg(type_count = pd.NamedAgg("date", "count"))
type_line_plot = ggplot(firecalls_count_df, aes(x = "date", y = "type_count", group = "type", color = "type"))\
+ geom_line()\
+ scale_x_datetime(breaks=date_breaks('3 days'))\
+ theme(dpi = 350, aspect_ratio= .85, subplots_adjust={'right': 0.75},\
axis_text_x= element_text(angle = 25, hjust = 1))
print(type_line_plot)## <ggplot: (316581289)>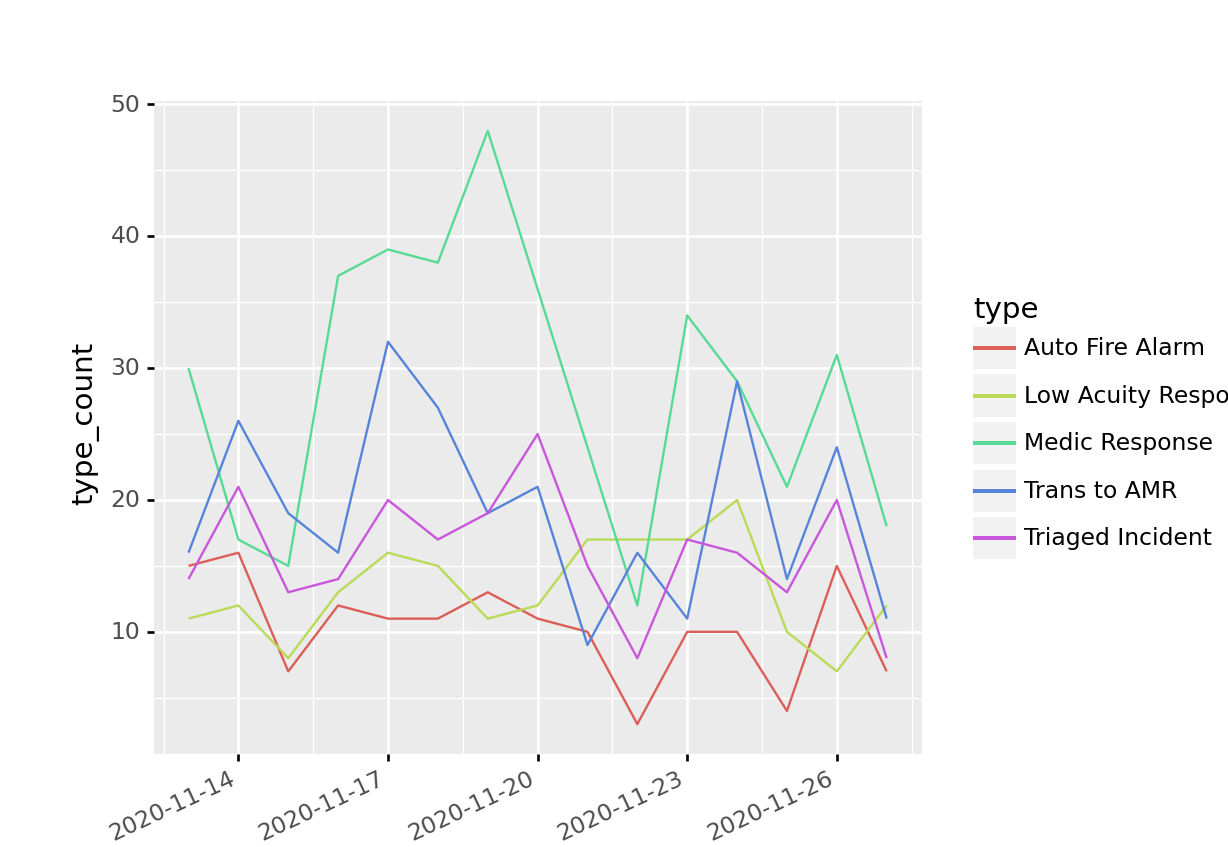 We filter our data to only include incidents in the top5_types series, and perform a simple type count, by date. We can then plot a color coded line-plot that illustrates the quantity of the top 5 incident types by date. This is just a simple example ilustrating how easy it is to perform some analysis on the data stored in your database.
We filter our data to only include incidents in the top5_types series, and perform a simple type count, by date. We can then plot a color coded line-plot that illustrates the quantity of the top 5 incident types by date. This is just a simple example ilustrating how easy it is to perform some analysis on the data stored in your database.
Further work and improvements.
As the cliche saying goes: “Hindsight is 2020”. There is some room for improvements to our ETL work flow. There are also some components we could add to increase the robustness of our analysis. A couple that come to mind are:
- Timezone handling.
- Reverse geo-coding
I recently encountered the timezone handling issue when I discovered that the UTC timezone doesn’t incur time change due to daylight savings. Therefore, after daylight savings occurred recently I was inadvertently querying for data in the future. I resolved this by increasing the time-delta between time zones, and back-filling the data that was missing. A package like pytz would resolve this issue, and would be able to give me the system date-time in PST, without having to manually calculate it like I currently do.
Reverse geo-coding is an improvement we can make to add some geographic components to our analysis. For example, we know that in our table cleanfirecalls, every row is an incident that resulted in the dispatch of fire fighters in Seattle. Almost all of those incidents contain a lat-long geo-spatial point. Geo-spatial points are great, but what if we want to analyze the quantity and types of calls in each Seattle neighborhood? That’s where reverse geo-coding comes in. The city of Seattle facilitates multiple geographic spatial files for different levels of granularity, such as neighborhoods, community reporting areas, and zip codes. This geospatial data will allow you to interpolate which neighborhood, zip code, or community the incident occurred. To garner such insight, we could have integrated a reverse geo-coding process in our work flow. This could add complexity to our simple work flow though, as null values could complicate the loading of data into the database. We could also geo-code after the loading of the data, direct that into a separate geo-coded table with multiple levels of geographic granularity per instance. I’m still not sure which way I’ll approach it, but the latter seems to be the simplest way forward.
In my next article I’ll be utilizing this data for analytics. So stay tuned!